Les Startups tunisiennes InstaDeep et iCompass annoncent que TunBERT, le premier modèle de traitement du langage naturel (NLP) au monde pour le dialecte tunisien est offert gratuitement et en open source pour stimuler davantage l’innovation dans un écosystème de technologie AI Tunisien en pleine croissance.
TunBERT est un modèle linguistique pour le dialecte tunisien qui, en appliquant les dernières avancées en matière d’intelligence artificielle (IA) et d’apprentissage automatique (ML), a été entraîné pour évaluer plusieurs tâches telles que l’analyse des sentiments, la classification des dialectes et les questions-réponses pour la compréhension écrite.


En rendant TunBERT disponible gratuitement à l’écosystème, InstaDeep et iCompass visent à ouvrir la voie à de nouvelles percées en recherche et développement sur multiples secteurs, accélérant ainsi l’innovation en fournissant une base sur laquelle d’autres peuvent s’appuyer pour construire des applications sur tous les domaine d’expertise.
“Nous sommes ravis de dévoiler TunBERT, un projet de recherche né d’une collaboration étroite entre iCompass et InstaDeep qui offre au dialecte tunisien une technologie de pointe. Ce travail illustre également le niveau d’excellence auquel peut aspirer l’écosystème technologique tunisien grâce à des collaborations entre les startups leaders en IA”, dit Karim Beguir, PDG et cofondateur d’InstaDeep.
Surmonter les variations dialectales et la mauvaise interprétation
« Nous sommes ravis de mettre nos résultats à la disposition de la communauté au sens large sachant que très peu de recherches ont été effectuées sur les langues sous-représentées dans le passé. Notamment, la mauvaise interprétation des variations dialectales représente un grand défi aujourd’hui puisque l’arabe parlé compte une large variété de dialectes régionaux, ce qui rend la NLP pour les dialectes particulièrement difficile, et il en va de même pour la langue tunisienne », explique Dr Hatem Haddad, CTO et Cofondateur d’iCompass.
Améliorer la diversité et assurer une meilleure représentation pour tous les peuples – et leur langues – est critique pour développer équitablement l’intelligence artificielle dans le futur.
TunBERT a suscité beaucoup d’intérêt à travers la Tunisie et au-delà depuis qu’InstaDeep et iCompass ont annoncé leur collaboration. En effet, le résultat de cet effort a été dévoilé lors d’une session dédiée co-présentée par Hatem Haddad, Cofondateur et CTO d’iCompass, et Nourchene Ferchichi, ingénieur IA chez InstaDeep, lors de la GPU Technology Conference (GTC) de NVIDIA en avril.
Parlé par 12 millions de personnes, le dialecte Tunisien est étroitement lié aux dialectes nord-africains qui sont parlés par environ 105 millions de personnes. Le plus grand défi en ce qui concerne le dialecte tunisien est qu’il s’agit d’une langue non standard car elle n’a pas de règles grammaticales. Le Tunisien est également considéré comme une langue sous-financée par rapport à d’autres langues (par exemple l’anglais), en raison de la rareté des bases de données publiques en dialecte Tunisien. Avec de nombreuses variations et interprétations, la traduction linguistique peut facilement être mal comprise et créer des réactions négatives de la part des autres arabophones. Par exemple:

Pour surmonter ces défis, les équipes de recherche d’InstaDeep et d’iCompass ont créé un ensemble de données de 67,2 Mo extrait des réseaux sociaux. La taille de l’ensemble de données peut sembler petite, mais combinée aux percées technologiques de l’IA en apprentissage profond, elle s’est avérée suffisante pour obtenir d’excellents résultats avec un modèle performant. De plus, l’équipe a utilisé le toolkit NeMo de NVIDIA, tirant parti d’une version optimisée du modèle BERT par NVIDIA pour adapter et affiner le réseau de neurones sous-jacent et enfin obtenir un modèle de langage (NLP) pré-entraîné sur un large corpus du dialecte tunisien.
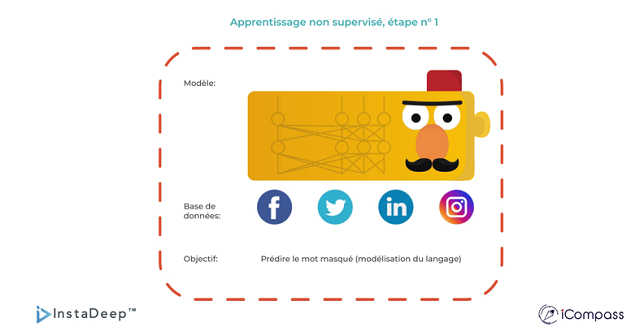
Pour évaluer les performances du modèle, l’équipe a mené des expériences de référence approfondies avec six ensembles de données pour trois tâches en aval: affiner TunBERT sur l’analyse des sentiments, l’identification du dialecte et les tâches de questions-réponses.

Examinons chaque tâche et les résultats obtenus par l’équipe de recherche.
TunBERT arrive à donner des résultats qui surpassent l’état de l’art sur le sujet quand il est utilisé avec plusieurs jeux de données labellisés. Comparé à des modèles plus larges tels que m-BERT, GigaBERT et AraBERT, TunBERT montre une meilleure représentation du dialecte tunisien et donne de meilleures performances tout en étant moins coûteux en calcul au moment de l’inférence.
Analyse des Sentiments:
Pour l’analyse des sentiments, l’équipe a comparé les performances de TunBERT avec plusieurs modèles, notamment Word2Vec, Doc2Vec et des modèles basés sur BERT tels que multilingual-BERT, GigaBERT et AraBERT. Les résultats montrent que TunBERT a surpassé ces modèles de manière significative sur des métriques comme l’exactitude (ou “accuracy”) et le F1 macro score.
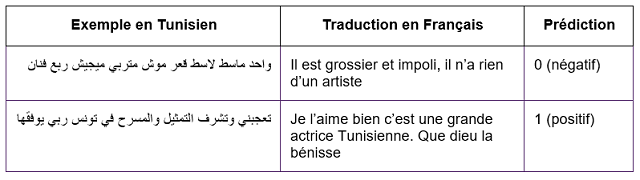
Les exemples dans ce tableau montrent les prédictions du modèle sur les ensembles de tests d’analyse des sentiments. Cela montre que le modèle est capable de distinguer correctement les commentaires positifs des commentaires négatifs.
Identification Dialectale
Pour travailler sur l’identification du dialecte, l’équipe a créé deux nouveaux ensembles de données (TAD) et (TADI), et a comparé les performances de TunBERT par rapport au multilingual-BERT, GigaBERT et AraBERT sur ces jeux de données. Les résultats montrent que TunBERT a nettement surpassé la performance de ces modèles sur la base de l’exactitude (ou “accuracy”) et le F1 macro score. Ceci montre clairement l’impact positif d’un modèle linguistique basé sur le dialecte sur une tâche aussi spécifique. De plus, le passage par un pré-entraînement avec des « données bruitées » au lieu de « données uniformes » s’est avéré utile dans ce cas spécifique.
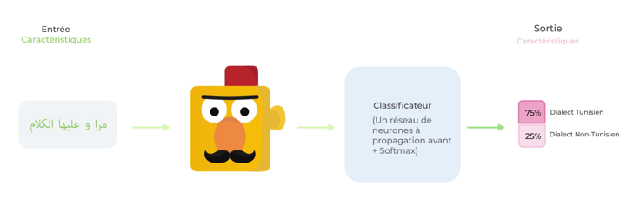
Le tableau suivant démontre la capacité de TunBERT à reconnaître le dialecte tunisien du dialecte égyptien, même si les deux dialectes nord-africains s’écrivent quasiment de la même manière.

Réponse aux Questions
En ce qui concerne la tâche de réponse aux questions, l’équipe a créé un jeu de donnée appelé TRCD (pour Tunisian Reading Comprehension Dataset), et a comparé les performances de TunBERT par rapport à BERT multilingues, GigaBERT et AraBERT, après avoir ajouté un pré-entrainement sur un jeu de donnée d’arabe moderne standard (MSA) à tous les modèles mentionnés précédemment.
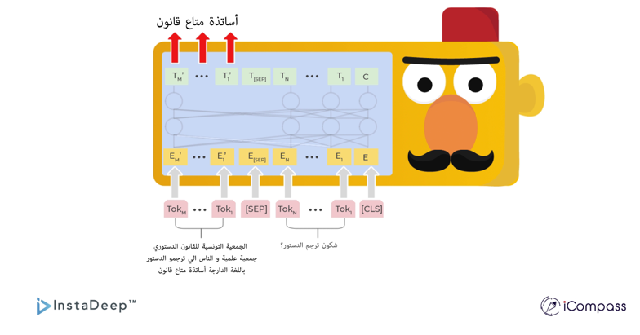
L’exemple ci-dessous présente les résultats des tests du modèle TunBERT sur des questions d’une version dialectale de la constitution tunisienne. Les réponses prédites attestent la compréhension de la question et du contexte du paragraphe par le modèle

Les résultats obtenus par TunBERT surpassent les recherches précédentes dans le domaine. Les résultats expérimentaux indiquent que le modèle TunBERT pré-entraîné apporte de réelles améliorations par rapport à d’autres modèles de langage basés sur BERT entraînés sur de larges jeux de données.
En rendant le modèle disponible en open source, ainsi que les jeux de données utilisés, InstaDeep et iCompass sont impatients de voir ce que la communauté africaine de recherche en IA pourra réaliser en utilisant TunBERT comme modèle de référence.
A propos d’InstaDeep
Fondé en 2014, InstaDeep est aujourd’hui un leader EMEA dans les produits d’IA d’aide à la décision pour l’entreprise, avec son siège à Londres et des bureaux à Paris, Tunis, Lagos, Dubaï et Le Cap. Avec une expertise à la fois dans la recherche en intelligence artificielle et dans les déploiements commerciaux concrets, la société offre un avantage concurrentiel à ses partenaires dans un monde axé sur l’IA. Tirant parti de son vaste savoir-faire en matière de calcul accéléré par carte graphique, d’apprentissage de réseaux de neurones et d’apprentissage par renforcement, InstaDeep a développé des produits, tels que sa plateforme de conception de protéines DeepChainTM, qui relèvent les défis les plus complexes dans une gamme diversifiée d’industries. InstaDeep a également développé des collaborations avec des leaders mondiaux de l’intelligence artificielle, tels que Google DeepMind, Nvidia et Intel.
A propos d’iCompass
iCompass est une startup tunisienne fondée en 2019 spécialisée dans les produits de traitement automatique des langues (NLP). iCompass utilise les dernières avancées dans l’apprentissage en profondeur (Deep Learning) et par renforcement (Reinforcement Learning) pour développer des chatbots ainsi que des services d’analyse numérique de réputation et d’assistance vocale. iCompass est aussi un leader de la région Moyen-Orient et Afrique grâce à son innovation dans la recherche et le développement dans le domaine du traitement automatique des langues (NLP). Les barrières linguistiques ne sont plus un obstacle et les nouveaux programmes développés par iCompass rendent possible l’application de ces technologies même aux dialectes Arabes et Africains.
Communiqué
